
Sebagai orang yang berkarir sebagai Data Analyst atau Data Scientist, pasti tidak asing dengan istilah Exploratory Data Analysis (EDA). EDA adalah kegiatan dalam melihat karakteristik dari data. EDA biasanya digambarkan hasilnya dengan bantuan rumus statistik dan grafik tertentu. Umumnya, EDA berfungsi untuk melihat gambaran umum mengenai pola pada suatu data.
Bagaimana cara melakukan Exploratory Data Analysis? Salah satu caranya adalah dengan menggunakan bahasa pemograman Python. Python adalah bahasa pemograman yang cukup populer saat ini utamanya dalam bidang pengolahan data.
Python sendiri memiliki banyak library yang memudahkan Data Analyst atau Data Scientist dalam melakukan analisis dan pengolahan data. Library yang umum digunakan oleh Data Analyst antara lain library Pandas, NumPy, SciPy, Matplotlib.
Disclaimer: Percobaan dalam menulis kode program dengan Python dapat dilakukan secara online di Google Colab. Bisa juga menggunakan notebook Kaggle.
Berikut adalah langkah-langkah umum dalam melakukan Exploratory Data Analysis dengan menggunakan Python untuk pemula.
1. Mengimpor library yang akan digunakan
Sebelum dapat digunakan, beberapa library tersebut harus diimpor terlebih dahulu dengan mengeksekusi kode berikut:
import pandas as pd
import numpy as np
Apa sih fungsi penggunaan dan impor library Pandas dan Numpy? Library Pandas digunakan untuk mengimpor file dataset dan mengolah dataframe sedangkan library Numpy digunakan untuk mengolah angka-angka. Secara umum, Pandas diimpor dengan nama pd dan numpy dengan nama np meskipun aturan sebenarnya membebaskan kita untuk memberi nama apapun.
2. Mengambil dan deklarasi dataset yang akan dianalisis
Lalu bagaimana cara untuk mengimpor dataset menggunakan library Pandas? Cara adalah dengan mengeksekusi kode berikut:
order_df = pd.read_csv("https://storage.googleapis.com/dqlab-dataset/order.csv")
order_df adalah nama variabel untuk menyimpan sebuah dataframe. Kamu bisa menamainya dengan sesuka hati. pd.read_csv adalah kode untuk membaca data dalam bentuk csv. Data yang akan kita baca adalah data yang berasal dari storage DQLab yaitu dataset order.
3. Melihat kontruksi dataframe yang akan dianalisis
Apa langkah selanjutnya? Selanjutnya adalah kita dapat mengetahui jumlah baris dan kolom dari dataset order_df.
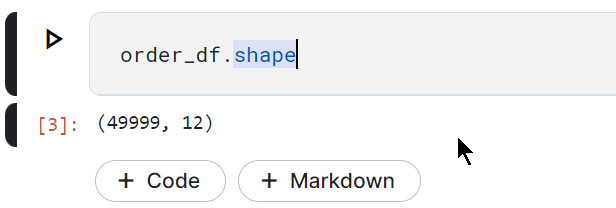
order_df.shape
Kode di atas akan menghasilkan jumlah kolom dan baris pada dataframe order_df. Hasilnya, order_df memiliki 49.999 baris dan 12 kolom.
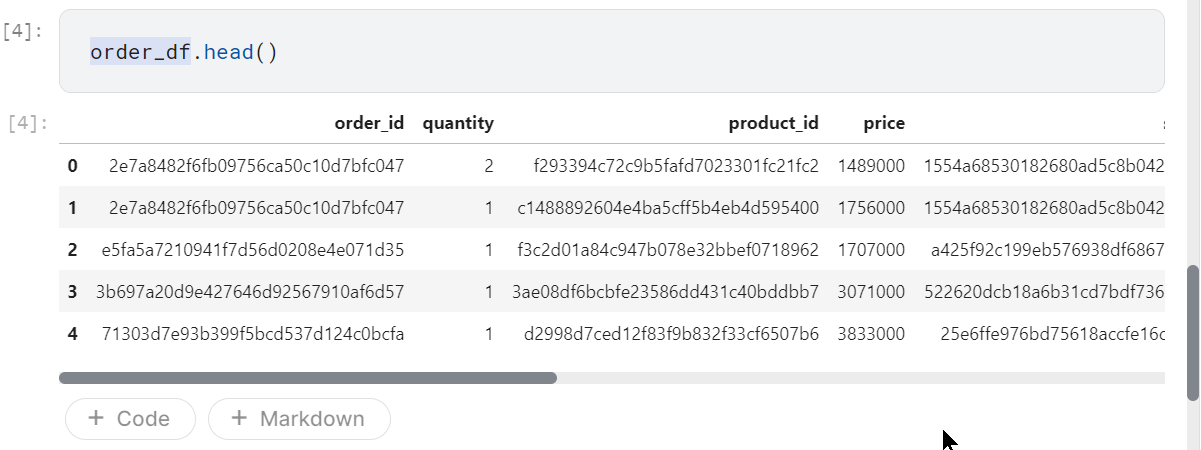
Selain itu, kita juga dapat melihat gambaran sekilas dari dataframe order_df dengan kode berikut:
Kode di atas akan menampilkan data lima teratas dan data lima terakhir dari dataframe order_df. Jika ingin menampilkan jumlah baris secara spesifik, bisa mengeksekusi dengan perintah head(10) atau tail(15).
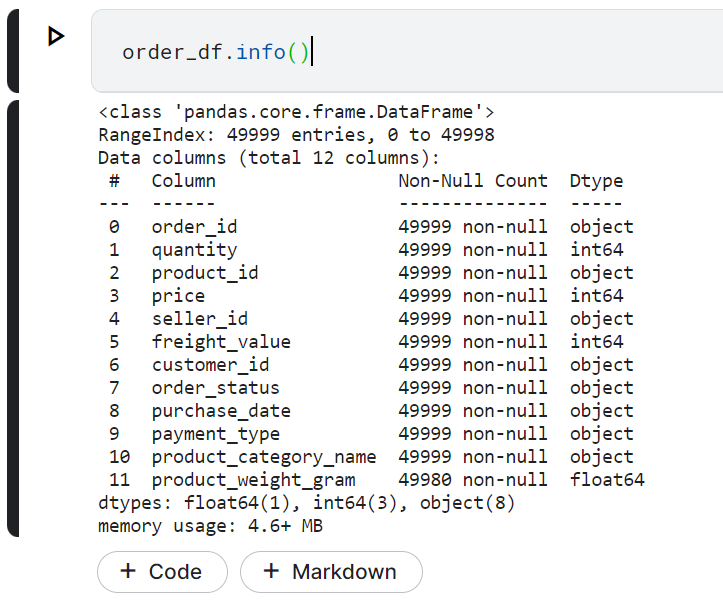
Kita perlu melihat tipe data dari masing-masing kolom.
order_df.info()
Kita juga perlu mengetahui apakah setiap kolom data terdapat missing value. Mengetahui jumlah missing value wajib bagi Data Analyst karena missing value memerlukan tindakan tertentu agar dataframe dapat dianalisis dengan hasil yang akurat.
order_df.isna().sum()

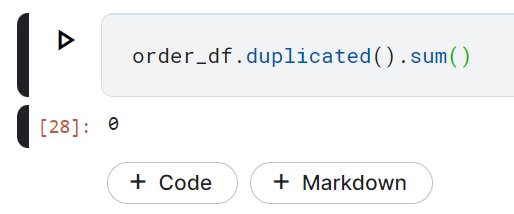
Cek juga apakah terdapat data yang duplikat.
Cek juga jumlah nunique value pada setiap kolom
order_df.nunique()
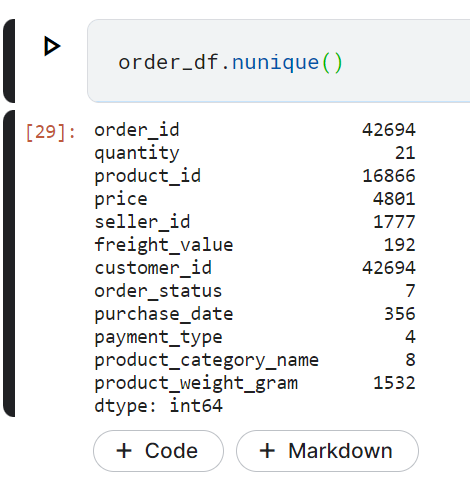
Kesimpulan: Terdapat missing value pada kolom product_weight_gram. Missing value ini akan dilakukan tindakan tertentu seperti dihapus, diisi dengan mean atau median dari keseluruhan data pada kolom tersebut.
3. Melihat statistik deskriptif pada dataframe
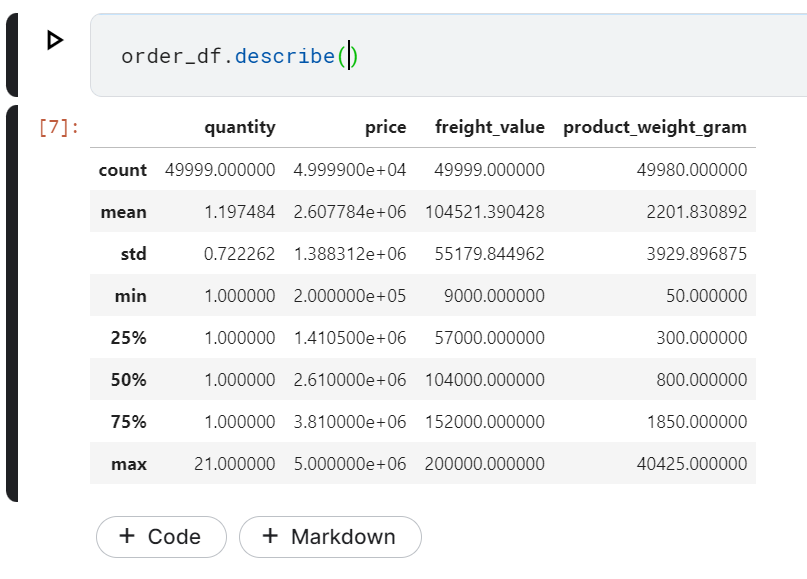
Dalam EDA, Data Analyst juga perlu untuk memeriksa statistik deskriptif pada dataframe yang dianalisis. Caranya adalah dengan eksekusi kode berikut.
order_df.describe()
Hasilnya adalah daftar statistik deskriptif pada kolom yang memiliki data numerik. Akan terlihat total count, mean, dan lain-lain pada setiap kolom.
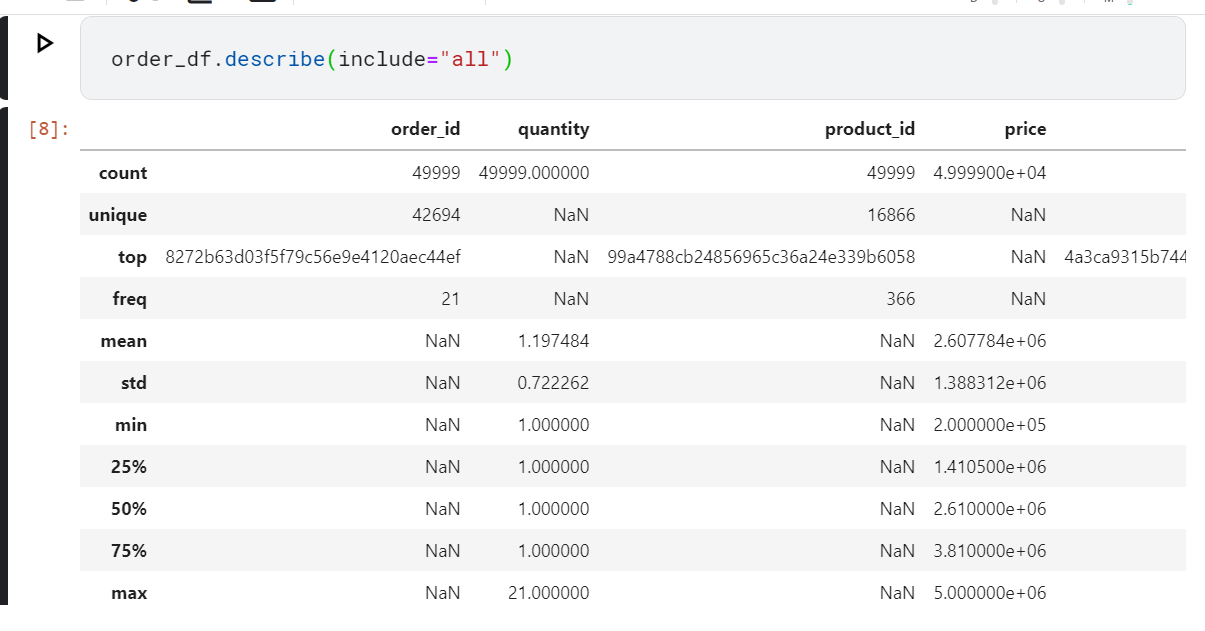
Jika ingin melihat statistik deskriptif seluruh kolom, coba eksekusi kode berikut.
order_df.describe(include="all")
Hasilnya adalah statistik deskriptif seluruh kolom baik kolom data numerik dan kolom data kategorikal.
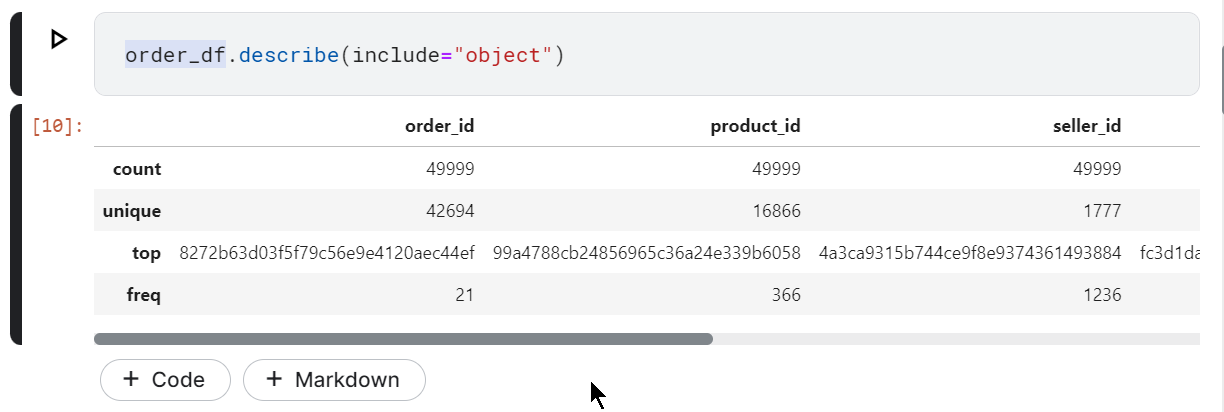
Untuk mengetahui statistik deskriptif kolom data kategorikal yang terdiri dari count, frekuensi, dan unique value bisa menggunakan kode berikut.
order_df.describe(include="object")
4. Membuat histogram untuk melihat distribusi data
Langkah selanjutnya adalah kita perlu mengimpor library lain agar bisa membuat histogram.
import matplotlib.pyplot as plt
Kita akan melihat distribusi data pada kolom 'price' dengan menggunakan histogram. Eksekusi kode berikut.
order_df[['price']].hist(figsize=(7, 5), bins=10, xlabelsize=8, ylabelsize=8)
plt.show()

Atau bisa juga dengan kode berikut untuk membuat histogram dari seluruh kolom data numerik.
order_df.hist(figsize=(15,10))

5. Menemukan Outliers
Dalam suatu data, terdapat suatu permasalahan yaitu adanya outliers. Apa itu outliers? Outliers adalah data yang memiliki nilai menyimpang atau paling berbeda dari nilai-nilai lain yang ada pada kelompoknya.

Outliers dapat ditemukan jika memenuhi dua kondisi berikut
data < Q1 - 1.5 * IQRdata > Q3 + 1.5 * IQR
Untuk mendapatkan nilai IQR, bisa dengan eksekusi kode berikut.

Lalu eksekusi kode berikut untuk mengetahui keberadaan outliers. Jika muncul nilai True, berarti ada outlier pada kolom data tersebut.
print((order_df < (Q1-1.5*IQR)) | (order_df > (Q3+1.5*IQR)))
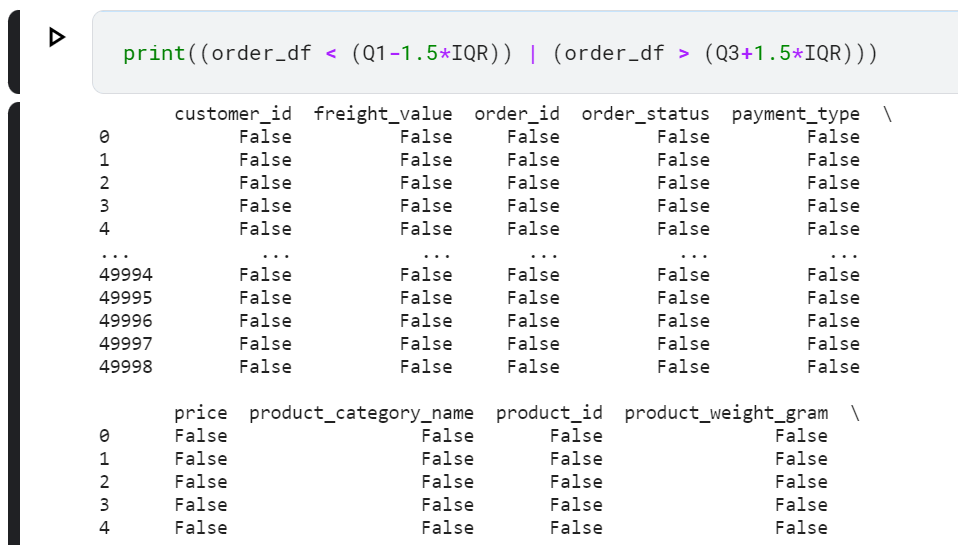
Sebenarnya, untuk frekuensi data dalam jumlah besar seperti order_df, pencarian outliers bisa dilakukan dengan cara membuat diagram. Penggambaran diagram pada setiap kolom numerik pada dataframe order_df membantu mempermudah dalam menemukan outliers. Diagram yang bisa dipakai untuk menemukan outliers adalah diagram boxplot.
order_df.boxplot(figsize=(15,7))

Kesimpulan: kolom quantity dan product_weight_gram memiliki outliers. Outliers ini akan dibuang pada data preprocessing. Outliers perlu dihilangkan agar model machine learning dapat menghasilkan prediksi lebih baik.
6. Eksplorasi lebih lanjut
Pada tahap ini, kita harus berkreasi untuk membedah isi data secara lebih rinci. Cara paling mudah dan jelas adalah dengan membuat diagram. Cara paling sederhana adalah menghitung total kuantitas pada setiap kolom data kategorikal. Contohnya adalah sebagai berikut.
plt.figure(figsize = (10, 5))
sns.countplot(order_df['product_category_name'])

plt.figure(figsize = (15, 5))
sns.countplot(order_df['order_status'])

sns.countplot(order_df['payment_type'])

Mengubah tipe data pada kolom purchase_date dari tipe data object menjadi date. Lalu memecah kolom purchase_date menjadi kolom tahun dan kolom bulan. Tak lupa untuk menambah dua kolom tersebut ke order_df.
purchase_date = pd.to_datetime(order_df['purchase_date'])
purchase_year = purchase_date.dt.year
purchase_month = purchase_date.dt.month
order_df['purchase_year'] = purchase_year
order_df['purchase_month'] = purchase_month
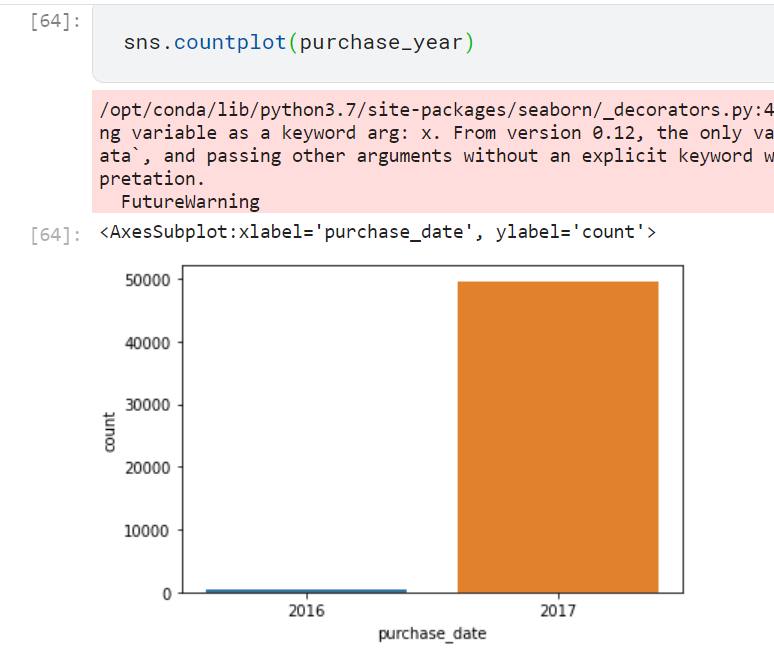
Tak lupa untuk melihat total pembelian setiap tahun.
sns.countplot(purchase_year)
order_df['order_id'].groupby(order_df['purchase_year']).count()
purchase_in_2016 = (372/(372+49627))*100
purchase_in_2017 = (49627/(372+49627))*100
print('Percentage of purchase in 2016 is : ' ,purchase_in_2016)
print('Percentage of purchase in 2017 is : ' ,purchase_in_2017)

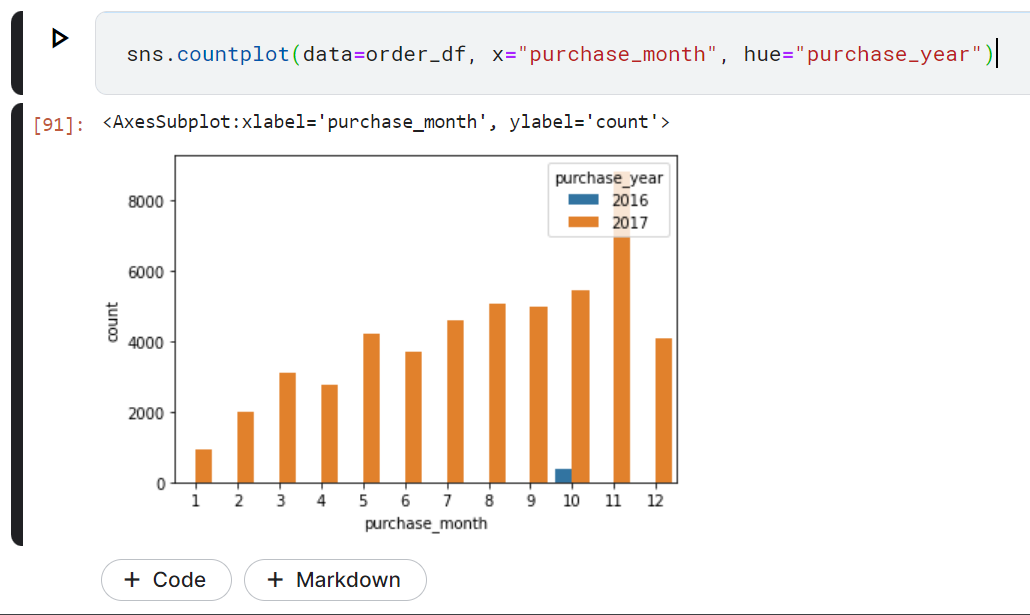
order_df['order_id'].groupby([order_df['purchase_month'], order_df['purchase_year']]).count()

sns.countplot(data=order_df, x="purchase_month", hue="purchase_year")
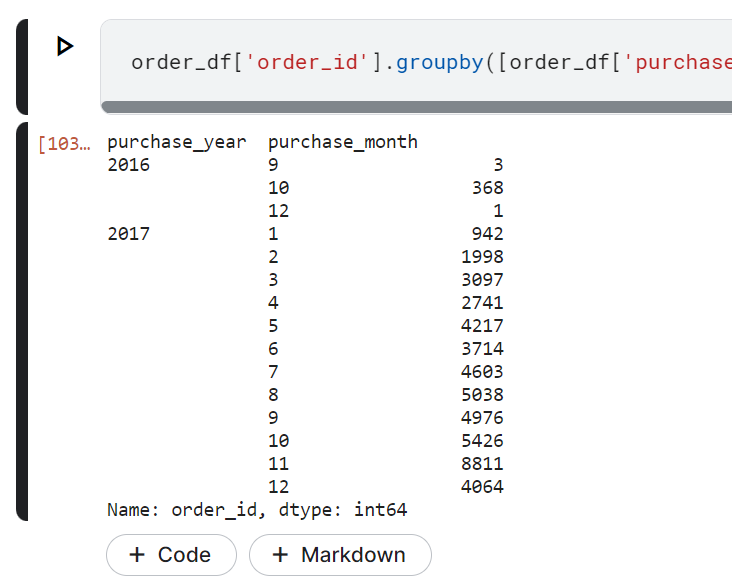
order_df['order_id'].groupby([order_df['purchase_year'], order_df['purchase_month']]).count()
Kesimpulan dari hasil Exploratory Data Analysis
- Penjualan paling banyak terjadi pada tahun 2017 dengan presentase 99% dibandingkan pada tahun 2016 yang memiliki sedikit sekali riwayat penjualan
- Pada tahun 2016, penjualan hanya terjadi pada tiga bulan yaitu bulan September, Oktober, dan Desember
- Penjualan paling sedikit adalah pada bulan Desember 2016 dimana penjualan hanya terjadi satu kali.
- Penjualan paling banyak terjadi pada November 2017 dengan total 8811 kali
- Tidak ada perbedaan signifikan terhadap empat pilihan metode pembayaran yang dipakai oleh konsumen.
- Tidak ada perbedaan signifikan terhadap kategori produk yang dibeli oleh konsumen.
- Hampir seluruh pembelian memiliki status order delivered.
- Penjualan mengalami naik turun secara bertahap hingga mengalami kenaikan signifikan pada November 2017. Setelah itu, penjualan menurun cukup signifikan sekitar 50% pada bulan Desember 2017
Dalam melakukan Exploratory Data Analysis, diperlukan banyak latihan agar intuisi kita dalam mengutak-atik data menjadi semakin berkembang. Banyak hal yang masih perlu dieksplorasi dari data penjualan ini. Misalnya adalah hubungan antar kolom satu dengan kolom lainnya mungkin bisa lebih dikulik lagi.






{kind=link}
Posting Komentar
Posting Komentar